
Veljko Milutinovic
MTP:
Understanding the Essence
UNDERSTANDING THE MTP
Basic classification:
coarse grain (task level; switching to a new thread on a context switch)
versus
fine grain (instruction level; switching to a new thread every cycle)
Principal components:
Multiple activity specifiers (program counters, stack pointers, etc.)
Multiple register contexts
Thread synchronization mechanism
(memory tags, HEP; 2-way joins, Monsoon; futures, MASA; etc.)
Fast context switch (Iannucci; Culler; etc.)
Differences between a thread and a process:
Thread may be directly supported at the architecture level
(start/suspension/continuation may be implemented in the ISA)
Process is implemented in the operating system layer
(start/suspension/continuation implemented in software)
COARSE-GRAINED MULTITHREADING
THE FIRST MULTITHREADING PROJECT: HEP
The first commercial MIMD based on multithreading (Denelcor, Inc., 1978)
Up to 16 PEMs (each one running up to 8 user and 8 supervisory threads)
and a number of DMMs (with dataflow heritage)
on a multistage ICN (any memory location accessible to any processor)
OTHER MULTITHREADING PROJECTS: 90’s
Tera (Smith, Tera)
Monsoon (Arvind, MIT and Motorola)
*T (Arvind, MIT and Motorola)
Super Actor Machine (Gao, McGill)
EM-4 (Sakai/Yamaguchi/Kodama, ETL)
MASA (Halstead/Fujita, Multilisp)
J-Machine (Dally, MIT)
Alewife (Agarwal, MIT)
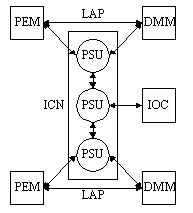
Figure MTPU1:
Structure of the HEP multiprocessor system (source: [Iannucci94])Legend:
PEM—Processing Element Module
DMM—Data Memory Module
PSU—Packet Switch Unit
LAP—Local Access Path
ICN—Interconnection Network
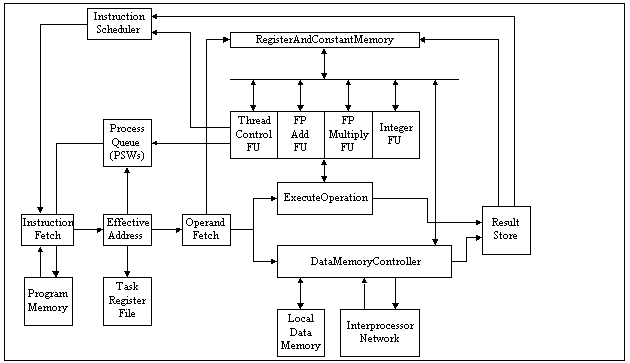
Figure MTPU2:
Structure of the HEP processing element module (source: [Iannucci94])Legend:
FU—Functional Unit,
FP—Floating-Point.
FINE-GRAINED MULTITHREADING
TRADITIONAL FINE-GRAINED MULTITHREADING: TFM
In traditional fine-grain multithreading:
only one thread issuing instructions in each cycle.
SIMULTANEOUS MULTITHREADING: SMT
Several independent threads issuing instructions simultaneously
to multiple functional units of a superscalar (in a single cycle).
Higher potentials for utilization of resources in a wide-issue processor.
Throughput on an 8-issue processor:
4 times of a superscalar and 2 times of a fine-grained multithread,
because both horizontal and vertical waste are attacked simultaneously

Figure MTPU3:
Empty issue slots: horizontal waste and vertical waste (source: [Tullsen95])Legend: Self-explanatory
Superscaling not efficient for vertical waste;
multithreading not efficient for horizontal waste;
the SMT is never not efficient!
|
Source of Wasted Issue Slots |
Possible Latency-Hiding or Latency-Reducing Techniques |
|
instruction TLB miss, |
decrease the TLB miss rates (e.g., increase the TLB sizes); |
|
I cache miss |
larger, more associative, or faster instruction cache hierarchy; |
|
D cache miss |
larger, more associative, or faster data cache hierarchy; |
|
branch misprediction |
improved branch prediction scheme; |
|
control hazard |
speculative execution; |
|
load delays (first-level cache hits) |
shorter load latency; |
|
short integer delay |
improved instruction scheduling |
|
long integer, |
(multiply is the only long integer operation, |
|
memory conflict |
(accesses to the same memory location in a single cycle) |
Figure MTPU4:
Causes of wasted issue slots and related prevention techniques (source: [Tullsen95])Legend:
TLB—Translation Lookaside Buffer.
All these techniques have to be utilized properly,
before the effects of SMT can be studied.
|
Purpose of Test |
Common Elements |
Specific Configuration |
T |
|
Unlimited FUs: |
Test A: FUs = 32 |
SM: 8 thread, 8-issue |
6.64 |
|
equal total issue bandwidth, |
IssueBw = 8, RegSets = 8 |
MP: 8 1-issue |
5.13 |
|
equal number of register sets |
Test B: FUs = 16 |
SM: 4 thread, 4-issue |
3.40 |
|
(processors or threads) |
IssueBw = 4, RegSets = 4 |
MP: 4 1-issue |
2.77 |
|
|
Test C: FUs = 16 |
SM: 4 thread, 8-issue |
4.15 |
|
|
IssueBw = 8, RegSets = 4 |
MP: 4 2-issue |
3.44 |
|
Unlimited FUs: |
Test D: |
SM: 8 thread, 8-issue, 10 FU |
6.36 |
|
Test A, but limit SM to 10 FUs |
IssueBw = 8, RegSets = 8 |
MP: 8 1-issue procs, 32 FU |
5.13 |
|
Unequal issue BW: |
Test E: FUs = 32 |
SM: 8 thread, 8-issue |
6.64 |
|
MP has up to four times |
RegSets = 8 |
MP: 8 4-issue |
6.35 |
|
the total issue bandwidth |
Test F: FUs = 16 |
SM: 4 thread, 8-issue |
4.15 |
|
|
RegSets = 4 |
MP: 4 4-issue |
3.72 |
|
FU utilization: |
Test G: FUs = 8 |
SM: 8 thread, 8-issue |
5.30 |
|
equal FUs, equal issue bw, unequal reg sets |
IssueBw = 8 |
MP: 2 4-issue |
1.94 |
Figure MTPU5:
Comparison of various (multithreading) multiprocessors and an SMT processor (source: [Tullsen95])Legend:
T—Throughput (instructions/cycle)
Current microprocessors are mostly 4-issue superscalars;
potentially, SMT leads to 8-issue and 16-issue next-gen superscalars.
REFERENCES
[Iannucci94] Iannucci, R. A., Gao, G. R., Halstead, R. H. Jr., Smith, B.,
Multithreaded Computer Architecture:
A Summary of the State of the Art,
Kluwer Academic Publishers, Boston, Massachusetts, USA, 1994.
[Tullsen95] Tullsen, D. M., Eggers, S. J., Levy, H. M.,
"Simultaneous Multithreading: Maximizing On-Chip Parallelism,"
Proceedings of the ISCA-95, Santa Margherita Ligure, Italy, 1995, pp. 392–403.
Veljko Milutinovic
MTP:
State of the Art
AN INDUSTRIAL MTP PROCESSOR
Problem:
Memory accesses are starting to dominate execution time of uniprocessors
Solution:
Coarse grained uniprocessor multithreading in the IBM environment
Conditions:
Object oriented programming for on-line transactions processing
Reference:
[Eickmeyer96] Eickmeyer, R. J., Johnson, R. E., Kunkel, S. R., Liu, S.,
Sqillante, M. S.,
"Evaluation of Multithreaded Uniprocessor
for Commercial Application Environments,"
Proceedings of the ISCA-96, Philadelphia, Pennsylvania,
May 1996, pp. 203–212.
AN ACADEMIC SMT PROCESSOR
Problem:
Extending a conventional wide-issue superscalar to SMT
Solution:
Combining of the following principles:
(a) minimizing the changes to the conventional superscalar architecture
(b) making the single thread case to be suboptimal (2%)
(c) achieving maximal throughput when running multiple threads
Throughput improvement: 5.4 (smt) over 2.5 (equivalent superscalar)
Conditions:
Eight threads with a modified Multiflow compiler
Reference:
[Tullsen96] Tullsen, D. M., Eggers, S.J., Emer, J. S., Levi, H. M., Lo, J.L.,
Stamm, R. L.,
"Exploiting Choice: Instruction Fetch and Issue
on an Implementable Simultaneous Multithreading Processor,"
Proceedings of the ISCA-96, Philadelphia, Pennsylvania,
May 1996, pp. 191–202.
Veljko Milutinovic
MTP:
IFACT
Combining Catalytic Migration
and Catalytic Reincarnation
Essence:
References:
[Milutinovic96a] Milutinovic, V.,
"Some Solutions for Critical Problems
in Distributed Shared Memory,"
IEEE TCCA Newsletter, September 1996.
[Milutinovic96b] Milutinovic, V.,
"The Best Method for Presentation of Research Results,"
IEEE TCCA Newsletter, September 1996.