
Veljko Milutinovic
ILP:
Understanding the Essence
UNDERSTANDING THE ILP
Methods to exploit the ILP:
Superscalar processing (SS), superpipelined processing (SP), and VLIW
ILP: A measure of the average number of instructions
that an SS/SP/VLIW processor might be able to execute at the same time
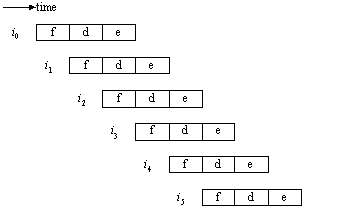
Figure ILPU1:
Instruction timing in a RISC processor without memory limitations (source: [Johnson91])Legend:
i—instruction, f—fetch, d—decode, e—execute.
SUPERSCALAR PROCESSING
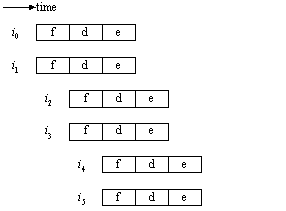
Figure ILPU2:
Instruction timing in a SUPERSCALAR processor without memory limitations (source: [Johnson91])Legend: Self-explanatory.
Instruction timing in a superscalar processor
ILP: A function of the number of dependencies
in relation to other instructions
MLP: A measure of the ability of a superscalar processor
to take advantage of the ILP
Must be balanced: MLP and ILP!
Fundamental performance limitations of a superscalar processor
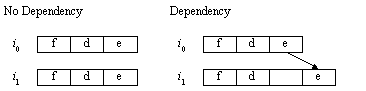
Figure ILPU3:
True data dependencies—effect of true data dependencies on instruction timing (source: [Johnson91])Legend: Self-explanatory.
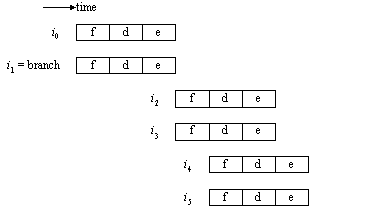
Figure ILPU4:
Procedural dependencies—effect of procedural dependencies on instruction timing (source: [Johnson91])Legend: Self-explanatory.
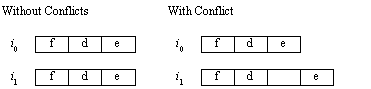
Figure ILPU5:
Resource conflicts—effect of resource conflicts on instruction timing (source: [Johnson91])Legend: Self-explanatory.

Figure ILPU6:
Resource conflicts—effect of resource conflicts on instruction timing (source: [Johnson91])Legend: Self-explanatory.
Out-of-order instruction issue, execution, and completion (state change)
An example from [Johnson91]:
I1 requires 2 cycles to execute
I3 and I4 conflict for a functional unit
I5 depends on a datum generated by I4
I5 and I6 conflict for a functional unit
In-order issue with in-order completion
|
Decode |
|
Execute |
|
Writeback |
Cycle |
||||
|
I1 |
I2 |
|
|
|
|
|
|
|
1 |
|
I3 |
I4 |
|
I1 |
I2 |
|
|
|
|
2 |
|
I3 |
I4 |
|
I1 |
|
|
|
|
|
3 |
|
|
I4 |
|
|
|
I3 |
|
I1 |
I2 |
4 |
|
I5 |
I6 |
|
|
|
I4 |
|
|
|
5 |
|
|
I6 |
|
|
I5 |
|
|
I3 |
I4 |
6 |
|
|
|
|
|
I6 |
|
|
|
|
7 |
|
|
|
|
|
|
|
|
I5 |
I6 |
8 |
Figure ILPU7:
Example II (source: [Johnson91])Legend: II—In-order issue, In-order completion.
Although simple, not used even in scalar microprocessors,
because long-latency instructions become a performance-bottleneck.
In-order issue with out-of-order completion
r3 := r3 op r5 (1)
r4 := r3 + 1 (2)
r3 := r5 + 1 (3)
r7 := r3 op r4 (4)
|
Decode |
|
Execute |
|
Writeback |
Cycle |
||||
|
I1 |
I2 |
|
|
|
|
|
|
|
1 |
|
I3 |
I4 |
|
I1 |
I2 |
|
|
|
|
2 |
|
|
I4 |
|
I1 |
|
I3 |
|
I2 |
|
3 |
|
I5 |
I6 |
|
|
|
I4 |
|
I1 |
I3 |
4 |
|
|
I6 |
|
|
I5 |
|
|
I4 |
|
5 |
|
|
|
|
|
I6 |
|
|
I5 |
|
6 |
|
|
|
|
|
|
|
|
I6 |
|
7 |
Figure ILPU8:
Example IO (source: [Johnson91])Legend: IO—In-order issue, Out-of-order completion.
First used in scalar microprocessors,
to improve performance of LD and FP instructions.
Instruction issue is stalled in three cases:
Control hardware is responsible for stalling (complicated by exceptions)
Out-of-order issue with out-of-order completion
|
Decode |
|
Window |
|
Execute |
|
Writeback |
Cycle |
||||
|
I1 |
I2 |
|
|
|
|
|
|
|
|
|
1 |
|
I3 |
I4 |
|
I1, I2 |
|
I1 |
I2 |
|
|
|
|
2 |
|
I5 |
I6 |
|
I3, I4 |
|
I1 |
|
I3 |
|
I2 |
|
3 |
|
|
|
|
I4, I5, I6 |
|
|
I6 |
I4 |
|
I1 |
I3 |
4 |
|
|
|
|
I5 |
|
|
I5 |
|
|
I4 |
I6 |
5 |
|
|
|
|
|
|
|
|
|
|
I5 |
|
6 |
Figure ILPU9:
Example OO (source: [Johnson91])Legend: OO—Out-of-order issue, Out-of-order completion.
Instruction issue does not stop at the instruction creating a conflict,
because one or more subsequent instructions might be executable.
Instruction fetch and decoding while room in the instruction window.
Instruction issue from the window regardless of the original order.
Out-of-order issue introduces an additional constraint:
when instruction N + 1 destroys the input for instruction N.
VLIW
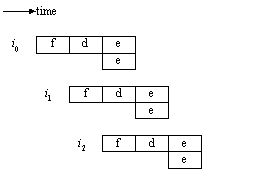
Figure ILPU10:
Instruction timing of a VLIW processor (source: [Johnson91])Legend: Self-explanatory.
Single instruction specifies more than one concurrent operation.
Less run-time instructions and more compile-time activities.
Difficult to make it binary-code compatible with existing processors.
Code size may increase if application/compiler not adequate.
Good for special purpose applications/compilations.
SUPERPIPELINED PROCESSING
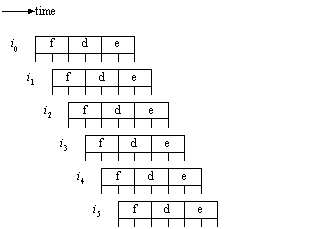
Figure ILPU11:
Instruction timing in a superpipelined processor (source: [Johnson91])Legend: Self-explanatory.
SP takes longer (1.5cp) to generate a result, compared to SS (1cp);
consequently, lower performance if more true data dependencies.
SP takes less (0.5cp) for simpler operations, compared to SS (1cp);
consequently, higher performance since test results are known sooner.
SP has a longer clock period, due to substage latches;
consequently, lower performance.
SP has less resources duplicated, due to resource timesharing;
consequently, lower complexity.
Good if clock skew controllable and resource duplication expensive.
HYBRID TECHNIQUES: SS, SP, and VLIW combined!
Theoretical limits of ILP exploitation:
(a) conditional branches;
(b) complexity grows quadratically with the issue width, and affects clock;
Practical limits of ILP exploitation:
(a) 8-way issue or equivalent in SS/SP (if hardware support only);
(b) N-op VLIW with trace scheduling (if compiler support included);
Delayed branching:
(a) The delay is longer, due to lookahead;
(b) The number of safe instructions is smaller, compared to the issue width;
Consequently, more sophisticated techniques are needed!
MIPS R10000
Fetching 4 instructions at a time from the I cache;
these instructions have been predecoded before being put into the I cache,
to help determine the instruction type immediately upon the I cache fetch.
After I cache fetch (512 entries), branches are predicted,
using a 512-entry prediction table within the I cache controller;
one table entry holds a 2-bit counter to encode the history information.
If a branch is predicted to be taken, it takes a cycle to redirect fetching;
instructions in the non-taken path are placed into the resume cache,
for the case of incorrect prediction (enough space for 4 predictions).
Fetch is followed by decoding,
register operands renaming (logical-to-physical mapping table updated),
and dispatching into one of non-FIFO I queues (easier due to predecoding).
Three I queues (memory, integer, and FP) with at most four I slots/queue;
four functional units
(address adder, integer unit with shifter, integer unit with fam, and fp unit).
On-chip primary data cache (32 Kbytes with 32-byte lines, 2w/sa);
off-chip secondary data cache;
using a reorder buffer to maintain precise state at the time of exception.
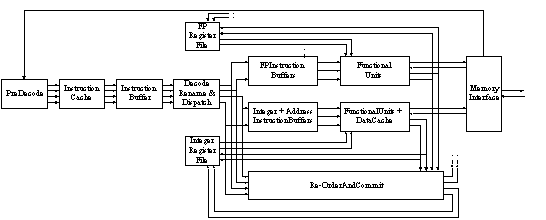
Figure ILPU12:
Organization of MIPS R10000 (source: [Smith95])Legend:
FP—Floating-point.
DEC Alpha21164
Simple superscalar going after high clock rate;
four instructions fetching from an 8Kbyte I cache,
and placed in one of two I buffers (four instructions in each one).
Issue goes from the buffers (in-order, no instructions bypassing at all);
one must be empty before the other one can be used
(simpler design, but slower issue).
Branches predicted using a 2-bit history table
associated within the I cache controller;
I issue stalled if 2nd branch encountered before the 1st branch resolved.
After fetch and decode, instructions are arranged
according to the functional unit they will use;
Issue follows after the operands are ready (from registers or via bypassing).
Four FUs: int with shifter, int with branchevalor, FP adder, FP multiplier;
integer instructions update registers in-order;
FP instructions update files out-of-order; not all FP exceptions are precise.
On-chip primary caches: 8Kbytes each (I + D, dm for 1cp cache access);
a 6-entry MAF with MissAddresses/TargetRegs
for up to 21 missed loads (merge).
On-chip secondary cache: 96Kbytes (shared, 3w/sa)
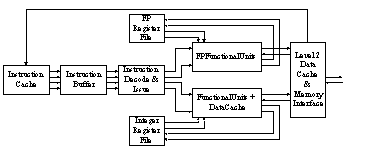
Figure ILPU12:
Organization of DEC Alpha21164 (source: [Smith95])Legend:
FP—Floating-point.
REFERENCES
[Johnson91] Johnson, M., Superscalar Microprocessor Design, Prentice-Hall, Englewood Cliffs, New Jersey, 1991.
[Smith95] Smith, J.E., Sohi, G., "The Microarchitecture of Superscalar Processors,"
Proceedings of the IEEE, Vol. 83, No. 12, December 1995, pp. 1609–1624.
Veljko Milutinovic
ILP:
State of the Art

OPTIMAL NUMBER OF FUs
FOR OUT-OF-ORDER
SUPERSCALAR PROCESSORS
Problem:
Number of FUs for maximal speed-up of modern SS microprocessors
(MC 88110, UltraSparc, DEC Alpha21164,
IBM 604 ooo, and MIPS R10000 ooo).
|
Processor DateShip |
PPC 604 94 |
MC 88110 92 |
UltraSparc 95 |
DEC 21164 95 |
MIPS 10000 95 |
|
Degree |
4 |
2 |
4 |
4 |
4 |
|
IntegerUnit |
2 |
2 |
2 |
2 |
2 |
|
ShiftUnit |
2 |
1 |
2 |
2 |
2 |
|
DivideUnit |
1 |
1 |
2 |
2 |
2 |
|
MultiplyUnit |
1 |
1 |
2 |
2 |
2 |
|
FPAddUnit |
1 |
1 |
2 |
1 |
1 |
|
ConvertUnit |
1 |
1 |
2 |
1 |
1 |
|
FPDivideUnit |
1 |
1 |
2 |
1 |
1 |
|
FPMultiplyUnit |
1 |
1 |
2 |
1 |
1 |
|
DataCachePort |
1 |
1 |
1 |
2 |
1 |
Figure ILPS1:
Basic characteristics of modern superscalar processors (source: [Jourdan95])Legend: Self-explanatory.
Solution:
From 5 to 9 FUs necessary to exploit the existing ILP,
using the modern microprocessor architectures.
If the degree of superscaling is 4 or more, several data cache ports are needed.
Conditions:
Real benchmark: Spec92
Lookahead window degree: 2 to 8
Effect of cache misses: n/a
Effect of ooo execution: assumed where not existing (unified issue buffer)
Reference:
[Jourdan96] Jourdan, S., Sainrat, P., Litaize, D.,
Exploring Configurations of Functional Units
in an Out-of-Order Superscalar Processor,
Proceedings of the ISCA-95, Santa Margherita Ligure, Italy,
May 1995, pp. 117–125.
INCREASING
THE CACHE PORT EFFICIENCY
FOR SUPERSCALAR PROCESSORS
Problem:
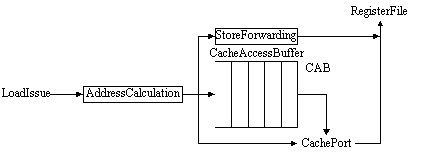
Figure ILPS4:
The load/store unit data path in modern SS microprocessors (source: [Wilson96])Legend:
CAB—Cache Address Buffer
Multiple cache ports are necessary for better exploitation of ILP;
however, they are expensive.
Solution:
Bandwidth of a single port can be improved,
by using additional buffering in the processor and wider ports in caches.
Four proposed hardware enhancements;
load all, load all wide, keep tags, and line buffer.
Conditions:
A 200 MHz R10000-like ISA with a 64-entry ROB and a 32-entry load/store buf;
Split primary caches (2w/sa:e8KB), unified secondary caches (2w/sa:2MB), MM;
Four miss status handling registers (MSHRs), to enable four on-going misses;
SimOS and Spec95.
Reference:
[Wilson96] Wilson, K. M., Olokotun, K., Rosenblum, M.,
Increasing Cache Port Efficiency
for Dynamic Superscalar Microprocessors,
Proceedings of the ISCA-96,
Philadelphia, Pennsylvania, May 1996, pp. 147–157.
REGION-BASED COMPILATION
Problem:
Traditionally, compilers have been built assuming functions as units of opt;
consequently, function boundaries hide valuable optimization opportunities.
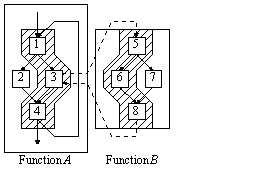
Figure ILPS2:
Example of an undesirable function-based code partition (source: [Hank95])Legend: Numbers refer to task units.
Solution:
Compiler is allowed to repartition the code into more desirable units,
in order to achieve more efficient code optimization.
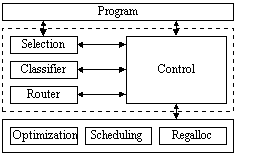
Figure ILPS3:
Example of a region-based compiler, inlining and repartition into regions (source: [Hank95])Legend: Self-explanatory.
Conditions:
Compilation units (CUs) selected by compiler, not by the software designer.
Optimal size of the CU, for better utilization of employed transformations.
Profiler support to determine regions for code closer to optimal.
Multiflow VLIW compiler with trace scheduling and register allocation.
Reference:
[Hank95] Hank, R. E., Hwu, W-m. W., Rau, B. R.,
Region-Based Compilation: An Introduction and Motivation,
Proceedings of the MICRO-28, Ann Arbor, Michigan, November/December 1995, pp. 158–168.
Veljko Milutinovic
ILP:
IFACT
A High-Level Language Oriented ILP
Essence:
References:
[Milutinovic87a] Milutinovic, V., Lopez-Benitez, N., Hwang, K.,
"A GaAs-Based Microprocessor Architecture
for Real-Time Applications,"
IEEE Transactions on Computers,
June 1987, pp. 714–727.
[Milutinovic87b] Milutinovic, V.,
"A Simulation Study
of the Vertical-Migration
Microprocessor Architecture,"
IEEE Transactions on Software Engineering,
December 1987, pp. 1265–1277.