
Veljko Milutinovic
DSM:
Understanding the Essence
Source: [Protic97] Protic, J., Tomasevic, M., Milutinovic, V.,
“Tutorial on Distributed Shared Memory (Lecture Transparencies),”
IEEE CS Press, Los Alamitos, California, USA, 1997.
Structure and Organization of a DSM System
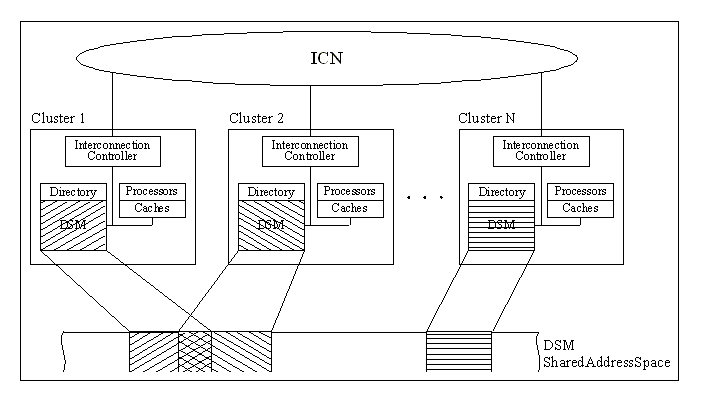
Figure DSMU1: Structure and organization of a DSM system (source: [Protic96]).
Legend:
ICN—Interconnection network.
Reference:
[Protic96a] Protic, J., Tomasevic, M., Milutinovic, V.,
“Distributed Shared Memory: Concepts and Systems,”
IEEE Parallel and Distributed Technology, Vol. 4, No. 2, Summer 1996, pp. 63–79.
DISTRIBUTED SHARED MEMORY
1. Combining the best of: SMP (programmability) and DCS (expandability)
2. Memory: physically distributed and logically compact
3. Implementing the DSM mechanism:
4. Implementing the DSM architecture:
5. Implementing the DSM algorithm:
6. Implementing the DSM management:
7. Implementing the coherence policy:
8. Implementing the memory consistency model:
9. New systems
10. New research avenues
MEMORY CONSISTENCY MODELS
Implementations of MCMs (hw-mostly vs sw-mostly):
Sequential: MEMNET+KSR1 vs IVY+MIRAGE
Delp/Farber(Delaware)+Frank(KSR) vs Li(Yale)+Fleish/Popek(UCLA)
Processor: RM vs PLUS
Gould/Encore/DEC(USA) vs Bisiani/Ravishankar/Nowatzyk(CMU)
Weak: TSO vs DSB
Release: Stanford-DASH vs Eager-MUNIN
Gharachorloo/Gupta/Hennessy(SU) vs Carter/Bennett/Zwaenopoel(Rice)
LazyRel: AURC vs TREADMARKS
Iftode/Dubnicki/Li(Princeton) vs Zwaenopoel/Keleher/Cox(Rice)
Entry: SCOPE vs MIDWAY
Iftode/Singh/Li(Princeton) vs Bershad/Zekauskas/Sawdon(CMU)
Important Issues:
Reference:
[Protic97] Protic, J., “A New Hybrid Adaptive Memory Consistency Model,”
Ph.D. Thesis, University of Belgrade, Belgrade, Serbia, Yugoslavia, 1997.
RELEASE CONSISTENCY
·
Dash: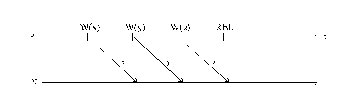
·
Munin: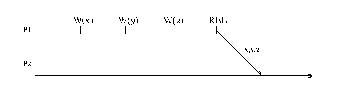
·
Repeated updates of cached copies: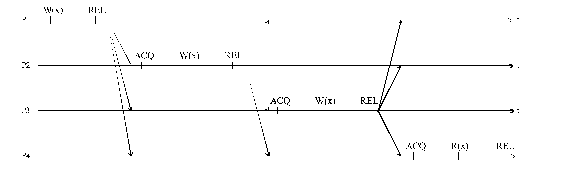
Figure DSMU2: Release consistency—explanation (source: [Lenoski92 + Carter91]).
Legend:
W—write,
REL—release,
ACQ—acquire.
LAZY RELEASE CONSISTENCY
·
Message traffic: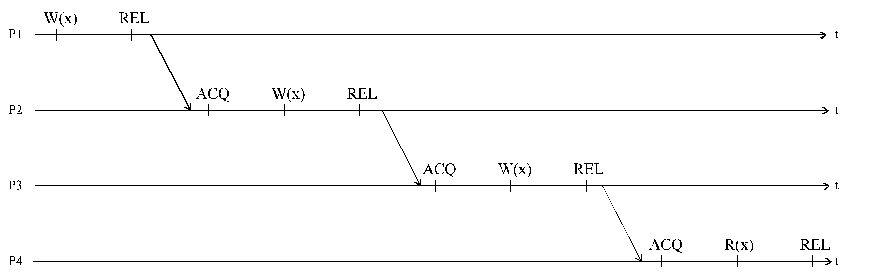
Figure DSMU3: Lazy release consistency—explanation (source: [Keleher94]).
Legend: Self-explanatory.
ENTRY CONSISTENCY

Figure DSMU5: Entry consistency—explanation (source: [Bershad93]).
Legend:
®
—protected by,n/n—not needed.
AUTOMATIC UPDATE RELEASE CONSISTENCY
·
Classical LRC: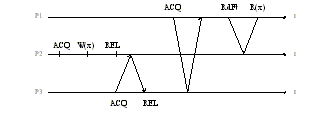
·
Copyset-2 AURC: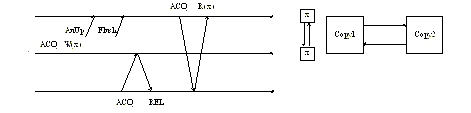
·
Copyset-N AURC: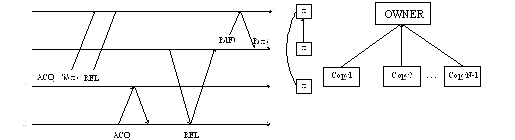
Figure DSMU4: AURC—explanation (source: [Iftode96a]).
Legend:
RdFt—read fault,
AuUp—automatic update.
AURC: Revisited
1. The hardware update mechanism works on the point-to-point basis.
Upon a write to a location, only one remote node is updated - the home,
no matter how many different nodes share that same data item.
2. The home for a specific page is determined at run time,
as the node which writes the first into a page.
It is assumed that the first writer will become the most frequent writer.
3. On the next acquire point, the acquiring node sends messages to the homes,
to obtain the current versions of all pages (in jurisdiction of these homes)
to be needed during the critical region which is just about to start.
4. Homes return the current version number of each page,
and the requesting node compares it with the version number
of the corresponding page in its possession.
5. The version at the node might be older,
but still usable,
if its version corresponds to the last update made by the same lock.
The current version might be #21, and the node may have the version #18,
but #18 may be the last version written to by the lock (process),
which is related to the acquire point in question.
If the node already has the last version of interest for it,
the page will not be ported over the network;
otherwise, it will.
6. The major issue here is to minimize the negative effects of false sharing,
in cases when page sizes are relatively large,
and several processes (locks) share the same page.
7. Home keeps the copy set (list of sharers) and the updated "version vector"
telling which locks were writing to a particular version of each page,
in the set of pages for which he/she is the home.
Each node keeps just one element of the "version vector."
This is the vector element related to the pages
replicated in that specific node.
8. During the execution of the code in the critical region,
the node will update both itself and the home,
on each write, as indicated earlier.
Others will be updated after they acquire the lock
and after they contact the home
to obtain the last update of the page.
This decreases the ICN traffic,
in comparison with some other reflective (write-through-update) schemes,
which update ALL sharers using a hardware reflection mechanism (RM and/or MC).
9. The above implements the lazy release consistency model
through a joint effort of hardware and software
(unlike TreadMarks, which does the entire work in software).
10. The AURC scheme has been implemented in the SHRIMP-II project
at Princeton.
Reference:
[Iftode96a] Iftode, L., Dubnicki, C., Felten, E., Li, K.,
“Improving Release-Consistent Shared Virtual Memory Using Automatic Update,”
Proceedings of the HPCA-2, San Jose, California, USA, February 1996, pp. 14–25.
SCOPE: Revisited
1. The SCOPE is the same as the AURC, except for the following differences.
2. The version update vector at the home includes one more field,
telling which variables (addresses) were written into,
by a given lock; this is repeated for each version of the page.
3. Consequently, the home is not checked at the next acquire point,
but after that point, when the variable is invoked,
which corresponds to the ENTRY consistency model.
4. However, unlike with the ENTRY, the activity upon invoking a variable
is related to the entire page,
i.e. the entire page is brought over, if so necessary,
5. This means page-based maintenance and more traffic,
rather than object-based maintenance and less traffic (like in Midway).
In principle, Midway can also do page-based maintenance, but it does not.
6. The SCOPE is faster, although it is page-based rather than object-based,
since it does a part of the protocol in hardware,
using the same automatic update hardware as the AURC.
7. In conclusion,
SCOPE can be treated as a hw/sw implementation of ENTRY.
8. Its advantage over ENTRY is in complete avoidance of compiler assistance.
9. The SCOPE was not implemented in any of the Princeton DSM machines.
10. The SCOPE research brings up a number of new ideas: merge, diff-avoid.
Reference:
[Iftode96b] Iftode, L., Singh, J. P., Li, K.,
“Scope Consistency: A Bridge Between RC and EC,”
Proceedings of the 8th ACM Symposium in Parallel Algorithms and Architectures, Padova, Italy, June 1996.
SOFTWARE IMPLEMENTED DSM
|
Name and Reference |
Type of Implementation |
Type of Algorithm |
Consistency Model |
Granularity Unit |
Coherence Policy |
|
IVY [Li88] |
user-level library + OS modification |
MRSW |
sequential |
1Kbyte |
invalidate |
|
Mermaid [Zhou90] |
user-level library + OS modifications |
MRSW |
sequential |
1Kbyte, 8Kbyte |
invalidate |
|
Munin [Carter91] |
runtime system + linker + library + preprocessor + |
type-specific (SRSW, MRSW, MRMW) |
release |
variable size objects |
type-specific (delayed update, invalidate) |
|
Midway [Bershad93] |
runtime system + compiler |
MRMW |
entry, release, processor |
4Kbyte |
update |
|
TreadMarks [Keleher94] |
user-level |
MRMW |
lazy release |
4Kbyte |
update, invalidate |
|
Blizzard [Schoinas94] |
user-level + OS kernel modification |
MRSW |
sequential |
32-128 byte |
invalidate |
|
Mirage [Fleisch89] |
OS kernel |
MRSW |
sequential |
512 byte |
invalidate |
|
Clouds [Ramachandran91] |
OS, out of kernel |
MRSW |
inconsistent, sequential |
8Kbyte |
discard segment when unlocked |
|
Linda [Ahuja86] |
language |
MRSW |
sequential |
variable (tuple size) |
implementation dependent |
|
Orca [Bal88] |
language |
MRSW |
synchronization dependent |
shared data object size |
update |
References:
[Ahuja86] Ahuja, S., Carriero, N., Gelernter, D., “Linda and Friends,” IEEE Computer, Vol. 19, No. 8, May 1986, pp. 26–34.
[Bal88] Bal, H., E., Tanenbaum, A., S., “Distributed Programming with Shared Data,”
International Conference on Computer Languages '88, October 1988, pp. 82–91.
[Li88] Li, K., “IVY: A Shared Virtual Memory System for Parallel Computing,”
Proceedings of the 1988 International Conference on Parallel Processing, August 1988, pp. 94–101.
[Carter91] Carter, J., B., Bennet, J. K., Zwaenepoel, W., “Implementation and Performance of Munin,”
Proceedings of the 13th ACM Symposium on Operating Systems Principles, October 1991, pp. 152–164.
[Bershad93] Bershad, B., N, Zekauskas M., J., Sawdon, W., A., “The Midway Distributed Shared Memory System,”
Proceedings of the COMPCON 93, February 1993, pp. 528–537.
[Fleissc89] Fleisch, B., Popek, G., “Mirage: A Coherent Distributed Shared Memory Design,”
Proceedings of the 14th ACM Symposium on Operating System Principles, ACM, New York, 1989, pp. 211–223.
[Keleher94] Keleher, P., Cox, A., L., Dwarkadas, S., Zwaenepoel, W.,
“TreadMarks: Distributed Shared Memory on Standard Workstations and Operating Systems,”
Proceedings of the USENIX Winter 1994 Conference, January 1994, pp. 115–132.
[Ramachandran91] Ramachandran, U., Khalidi, M., Y., A., “An Implementation of Distributed Shared Memory,”
Software Practice and Experience, Vol. 21, No. 5, May 1991, pp. 443-464.
[Schoinas94] Schoinas, I., Falsafi, B., Lebeck, A., R., Reinhardt, S., K., Larus, J., R., Wood, D., A.,
“Fine-grain Access Control for Distributed Shared Memory,”
Proceedings of the 6th International Conference on Architectural Support for Programming Languages
and Operating Systems, November 1994, pp. 297–306.
[Zhou90] Zhou, S., Stumm, M., McInerney, T.,
“Extending Distributed Shared Memory to Heterogeneous Environments,”
Proceedings of the 10th International Conference on Distributed Computing Systems, May-June 1990, pp. 30–37.
Figure DSMU6: A summary of software-implemented DSM (source: [Protic96a]).
Legend: OS—Operating System.
HARDWARE IMPLEMENTED DSM
|
Name and Reference |
Cluster Configuration |
Type of Network |
Type of Algorithm |
Consistency Model |
Granularity Unit |
Coherence Policy |
|
Memnet [Delp91] |
single processor, Memnet device |
token ring |
MRSW |
sequential |
32 bytes |
invalidate |
|
Dash [Lenoski92] |
SGI 4D/340 |
mesh |
MRSW |
release |
16 bytes |
invalidate |
|
SCI [James94] |
arbitrary |
arbitrary |
MRSW |
sequential |
16 bytes |
invalidate |
|
KSR1 [Frank93] |
64-bit custom PE, I+D caches, |
ring-based |
MRSW |
sequential |
128 bytes |
invalidate |
|
DDM [Hagersten92] |
4 MC88110s, |
bus-based |
MRSW |
sequential |
16 bytes |
invalidate |
|
Merlin [Maples90] |
40-MIPS computer |
mesh |
MRMW |
processor |
8 bytes |
update |
|
RMS [Lucci95] |
1-4 processors, caches, |
RM bus |
MRMW |
processor |
4 bytes |
update |
References
[Delp91] Delp, G., Farber, D., Minnich, R., “Memory as a Network Abstraction,”
IEEE Network, July 1991, pp. 34–41.
[Lenoski92] Lenoski , D., Laudon, J., et al., “The Stanford DASH Multiprocessor,”
IEEE Computer, Vol. 25, No. 3, March 1992, pp. 63–79.
[Lucci95] Lucci, S., Gertner, I., Gupta, A., Hedge, U., “Reflective-Memory Multiprocessor,”
Proceedings of the 28th IEEE/ACM Hawaii International Conference
on System Sciences,
Maui, Hawaii, U.S.A., January 1995, pp. 85–94.
[James94] James, D. V, “The Scalable Coherent Interface: Scaling to High-Performance Systems,”
COMPCON `94: Digest of Papers, March 1994, pp.64–71.
[Frank93] Frank, S., Burkhardt III, Rothnie, J.,
“The KSR1: Bridging the Gap Between Shared Memory and MPPs,”
COMPCON 93, February 1993, pp. 285–294.
[Hagersten92] Hagersten, E., Landin, A., Haridi, S., “DDM—A Cache-Only Memory Architecture,”
IEEE Computer, Vol. 25, No. 9, September 1992, pp. 44–54.
[Maples90] Maples, C., Wittie, L., “Merlin: A Superglue for Multicomputer Systems,”
COMPCON’90, March 1990, pp. 73–81.
Figure DSMU7: A summary of hardware-implemented DSM (source: [Protic96a]).
Legend:
RM—Reflective Memory,
RMS— Reflective Memory System,
SCI—Scalable Coherent Interface,
DDM—Data Difusion Machine.
HYBRID IMPLEMENTED DSM
|
Name and Reference |
Cluster Configuration + Network |
Type of Algorithm |
Consistency Model |
Granularity Unit |
Coherence Policy |
|
PLUS [Bisani90] |
M88000, 32K cache, |
MRMW |
processor |
4K bytes |
update |
|
Galactica Net [Wilson94] |
4 M88110s, 2-L caches |
MRMW |
multiple |
8K bytes |
update/ |
|
Alewife [Chaiken94] |
Sparcle PE, 64K cache, |
MRSW |
sequential |
16 bytes |
invalidate |
|
FLASH [Kuskin94] |
MIPS T5, I+D caches, |
MRSW |
release |
128 bytes |
invalidate |
|
Typhoon [Reinhardt94] |
SuperSPARC, 2-L caches, |
MRSW |
custom |
32 bytes |
invalidate custom |
|
Hybrid DSM [Chandra93] |
FLASH-like |
MRSW |
release |
variable |
invalidate |
|
SHRIMP [Iftode96] |
16 Pentium PC nodes, Intel Paragon routing network |
MRMW |
AURC, scope |
4Kbytes |
update/ invalidate |
References
[Bisani90] Bisani, R., Ravishankar M., “PLUS: A Distributed Shared-Memory System,”
Proceedings of the 17th Annual International Symposium on Computer Architecture,
Vol. 18, No. 2, May 1990, pp. 115–124.
[Chaiken94] Chaiken, D., Kubiatowicz, J., Agarwal, A.,
“Software-Extended Coherent Shared Memory: Performance and Cost,”
Proceedings of the 21st Annual International Symposium on Computer Architecture,
April 1994, pp. 314–324.
[Chandra93] Chandra, R., et al,
“Performance Evaluation of Hybrid Hardware and Software
Distributed Shared Memory Protocols,”
CSL-TR-93-597, Stanford University, December 1993.
[Iftode96] Iftode, L., Pal Singh, J., Li, K.,
“Scope Consistency: A Bridge Between Release Consistency and Entry Consistency,”
Proceedings of the 8th Annual Symposium on Parallel Algorithms and Architectures, June 1996.
[Kuskin94] Kuskin, J., Ofelt, D., Heinrich, M., Heinlein, J., Simoni, R., Gharachorloo, K., Chapin, J., Nakahira, D., Baxter, J., Horowitz, M., Gupta, A., Rosenblum, M., Hennessy, J.,
“The Stanford FLASH Multiprocessor,”
Proceedings of the 21st Annual International Symposium on Computer Architecture,
April 1994, pp. 302–313.
[Reinhardt94] Reinhardt, S., Larus, J., Wood, D., “Tempest and Typhoon: User-Level Shared Memory,”
Proceedings of the 21st Annual International Symposium on Computer Architecture,
April 1994, pp. 325–336.
[Wilson94] Wilson, A., LaRowe, R., Teller, M., “Hardware Assist for Distributed Shared Memory,”
Proceedings of the 13th International Conference on Distributed Computing Systems,
May 1993, pp. 246–255.
Figure DSMU8: A summary of hybrid hardware/software-implemented DSM (source: [Protic96a]).
Legend:
CMMU—Cache Memory Management Unit,
NP—Network Protocol.
Veljko Milutinovic
DSM:
State of the Art
S3.mp and BEYOND
Origin and Environment
[Nowatzyk93] Nowatzyk, M., Monger, M., Parkin, M., Kelly, E., Browne, M., Aybay, G., Lee, D.,
“S3.mp: A Multiprocessor in Matchbox,” Proceedings of the PASA, 1993.
[Saulsbury96] Saulsbury, A., Pong, F., Nowatzyk, A.,
“Missing the Memory Wall: The Case for Processor/Memory Integration,”
Proceedings of the ISCA, 1996, pp. 90–101.
The Sequent STiNG
Origin and environment
[Lovett96] Lovett, T., Clapp, R., “Sting,”
Proceedings of the IEEE/ACM ISCA-96,
Philadelphia, Pennsylvania, May 1996, pp. 308–317.
The IFACT RM/MC for Networks of PCs
Origin and Environment
a) Basic research and design in 1993
b) Board implementation and testing in 1994
c) Five different concept improvements for higher node counts:
[Savic95] Savic, S., Tomasevic, M., Milutinovic, V., Gupta, A., Natale, M., Gertner, I.,
“Improved RMS for the PC Environment.”
Microprocessors and Microsystems, Volume 19, Number 10, December 1995, pp. 609–619.
The DEC MC for NOWs
Origin and Environment
a) A PCI version of the IFACT RM/MC board
b) Digital UNIX cluster team: Better advantage of MC
c) Digital HPC team: Optimized application interfaces (including PVM)
d) Reason for adoption:
[Gillett96] Gillett, R.B., “Memory Network for PCI,” IEEE MICRO, February 1996, pp. 12–18.
The IFACT RM/MC for Infinity SP
Origin and Environment
a) Basic research in 1996
b) Goal: Continuing to be the highest performance I/O processor on planet
c) Five different ideas introduced for higher performance:
[Milutinovic96] Milutinovic, V. (Invited paper), “Solutions for Critical Problems of DSM: New Ideas to Analyze,”
IEEE TCCA Newsletter, September 1996.
Typhoon
Origin and Environment
[Reinhardt96] Reinhardt, S. K., Pfile, R. W., Wood, D .A., “Decoupled Hardware Support for DSM,”
Proceedings of the IEEE/ACM ISCA-96, Philadelphia, Pennsylvania, May 1996, pp. 34–43.
Veljko Milutinovic
DSM:
IFACT
The NextGen IFACT RM Board
Current Research
References
[Milutinovic95c] Milutinovic, V.,
“New Ideas for SMP/DSM,”
UBTR, Belgrade, Serbia, Yugoslavia, 1995.
[Milenkovic96a] Milenkovic, A., Milutinovic, V.,
“Cache Injection Control Architecture for RM/MC,”
Encore, Fort Lauderdale, Florida, USA, 1996.
[Milenkovic96b] Milenkovic, A., Milutinovic, V.,
“Memory Injection Control Architecture for RM/MC,”
Encore, Fort Lauderdale, Florida, USA, 1996.
[Jovanovic96] Jovanovic, M., Milutinovic, V.,
“Bypassing and Deletion for Better Performance,”
Encore, Fort Lauderdale, Florida, USA, 1996.
[Protic96b] Protic, J., Milutinovic, V.,
“Combining LRC and EC: Spatial versus Temporal Data,”
Encore, Fort Lauderdale, Florida, USA, 1996.