
Veljko Milutinovic
DPS: Basics
FIGHTING THE NEGATIVE EFFECTS
OF
CONTROL DEPENDENCIES: A SUMMARY
Essence:
Conversion of control dependencies into data dependencies.
Essence:
Execution of control-independent code in parallel,
while waiting for control transfer to take place
(multiple execution streams or delayed branch execution).
Essence:
Speculating the outcome of branch instructions,
doing speculative execution, and validation or reexecution.
Strategies - the same! Tactics - quite different!
FIGHTING THE NEGATIVE EFFECTS
OF
DATA DEPENDENCIES
1. ELIMINATION
through dependence collapsing by fusing [e.g., Montoye90],
or by other techniques [e.g., Milutinovic98].
2. CONCEALATION
through run-time efforts [e.g., Smith95],
or compile-time efforts [e.g., Hwu95].
SELECTED REFERENCES
[Gonzalez97] Gonzalez, J., Gonzalez, A.,
Speculative Execution via Address Prediction and Data Prefetching,
Proceedings of the 11th ACM 1997 International Conference on Supercomputing,
Vienna, Austria, July 1997, pp. 196-203.
[Hwu95] Hwu, W.W., et al.,
Compiler Technology for Future Microprocessors,
Proceedings of the IEEE, Vol. 83, No. 12, December 1995, pp. 1625-1640.
[Lipasti96] Lipasti, M.H., Shen, J.P.,
Exceeding the Dataflow Limit via Value Prediction,
Proceedings of the 29th International Symposium on Microarchitecture - MICRO-29,
Paris, France, December 1996, pp. 226-237.
[Milutinovic98] Milutinovic, V.,
"Surviving the Design of Microprocessor and Multimicroprocessor Systems:
Lessons Learned," IEEE CS Press, Los Alamitos, California, 1998.
[Montoye90] Montoye, R.K., Hokenek, E., Runyon, S.L.,
Design of the IBM RISC System/6000 Floating-Point Execution Unit,
IBM Journal of Research and Development,
Vol. 34, No. 1, January 1990, pp. 59-70.
[Smith95] Smith, J.E., Sohi, G.S.,
The Microarchitecture of Superscalar Processors,
Proceedings of the IEEE, Vol. 83, No. 12, December 1995, pp. 1609-1624.
MAJOR TECHNIQUES TO OVERCOME
THE NEGATIVE EFFECTS OF DATA DEPENDENCIES
SOME DATA VALUE PREDICTION TECHNIQUES
References:
[Sodani97] Sodani, A., Sohi, G.S.,
Dynamic Instruction Reuse,
Proceedings of the 24th Annual Int'l Symposium on Computer Architecture - ISCA-97,
Denver, Colorado, June 1997, pp. 194-205.
[Wang97] Wang, K., Franklin, M.,
Highly Accurate Data Value Prediction Using Hybrid Predictors,
Proceedings of the 30th Annual Symposium on Microarchitecture - MICRO-30,
Research Triangle Park, North Carolina, December 1997, pp. 281-290.
HOW FREQUENT ARE
THE VALUE-PRODUCING INSTRUCTIONS?
|
Program |
% |
|
go |
79 |
|
compress |
74 |
|
m88ksim |
72 |
|
li |
69 |
|
gcc |
57 |
Table1:
Percentage of Value-Producing Instructions (Dynamical Statistics)The DYNAMICAL INSTRUCTION REUSE Predictor
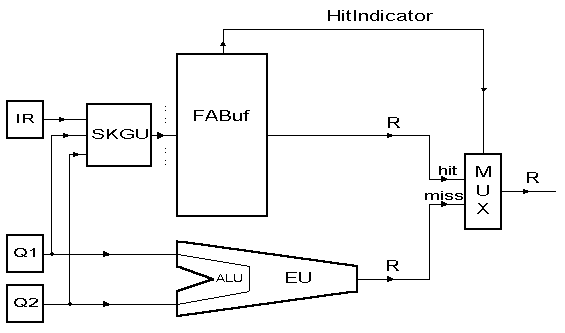
Essence
:
Figure1: Block Scheme of the Dynamical Instruction Reuse Predictor
Legend:
ALU - Arithmetic and Logic Unit
SKGU - Search Key Generator Unit
EU - Execution Unit
FABuf - Fully Associative Buffer
HitIndicator - Indicator of the Hit in the Fully Associative Buffer
Qi - Operand #1 (i=1,2)
R - Result
Result:
If a 1024-entry FABuf is used,
the execution part can be skipped
in about 33% of data-producing instructions (dynamical statistics).
The LAST OUTCOME Predictor
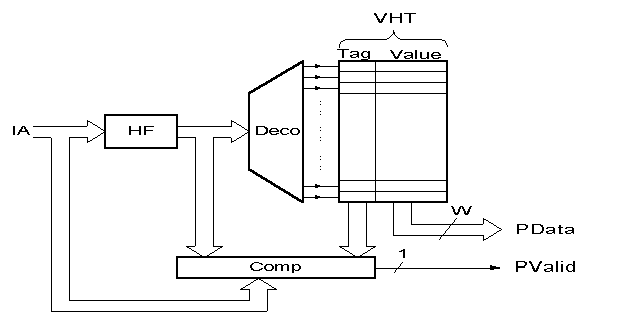
Essence:
Figure2: Block Scheme of the Last Outcome Predictor
Legend:
Comp - Comparator
Deco - Decoder
HF - Hash Function
IA - Instruction Address
PData - Predicted Data (W bits)
PValid - Prediction Valid indicator (one bit); just the VHT hit
Tag - Tag storing the identity of the currently mapped instruction
VHT - Value History Table
Value - Value produced during the last execution
of the currently mapped instruction
Result:
For the PowerPC architecture and the SPEC applications,
prediction accuracy is equal to:
49% - for the last ONE value, and
61% - for the last 4 values stored (predictor able to pick the right value)
CRUCIAL DESIGN PARAMETER: DATA VALUE LOCALITY
Too little history - poor prediction accuracy
Too much history - high hardware and time overheads
Architecture - MIPS R2000
Applications - SPEC'92
|
Program |
% |
|
go |
73 |
|
compress95 |
56 |
|
m88ksim |
91 |
|
li |
81 |
|
gcc |
75 |
Table2
: Percentage of Eligible Instructions Reusing 1 of the Last 16 Values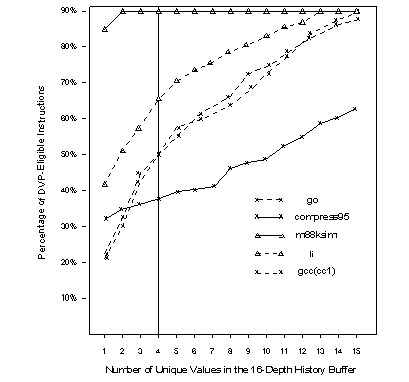
How many of the 16 values are unique?
Figure3
: Number of Unique Values in the Last-16-Buf of Eligible Instructions (Cumulative Distribution)X - Number of unique values in the last-16-buf of eligible instructions
Y - Percentage of register result producing instructions
with X or less unique values
Conclusions
[Wang97]:Case X=1 taken care of by the LAST OUTCOME predictor.
From 22% to 85% of instructions have all their last 16 results the same.
Case X=4 needs a more accurate predictor (knee is at approximately 4).
From 38% to 91% of instructions have 4 or fewer unique values in the last-16.
The STRIDE BASED Predictor
So far used successfully for data prefetching!
Figure4
: Block Scheme of the Stride Value Predictor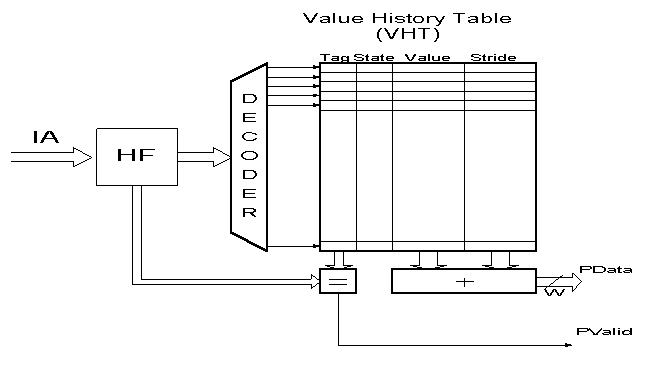
Fields:
The Stride Detection Phase
S1=D2-Value(VHT)
S1 - Stride
D2 - Value generated by the second instance of the instruction
Value(VHT) - Value generated by the first instance (D1)
After the computation is completed, the following updates are done:
A STABLE STRIDE DOES EXIST
IF THE NEXT RESULT CREATES THE STRIDE
WHICH IS THE SAME AS THE ONE IN THE VHT.
The following calculation is done:
S2=D3-Value(VHT)
The following updates are done:
{Steady} if S2=S1
{Transient} if S2<>S1 - no change of the STATE field
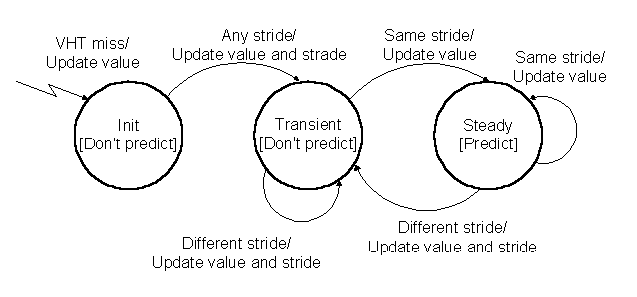
Figure5
: State Transition Diagram of the Stride Value PredictorThe TWO LEVEL VALUE Predictor
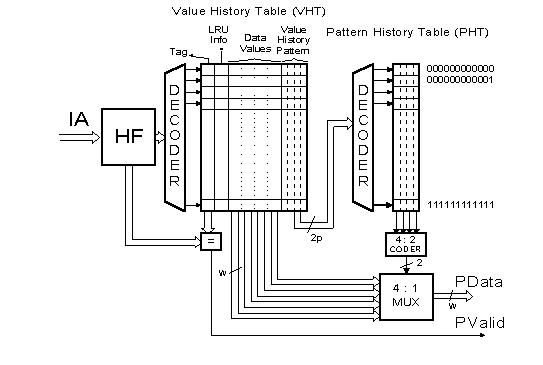
Figure6
: Block Scheme of a Two Level Value Predictor
The VHT (of the first level) has four fields
:TAG
the four values are associted with the encoding {00,01,10,11}
LRU - Keeping track of the order in which the 4 data values were seen;
when the fifth value appears, the least recently seen value goes out
VHP - Value History Pattern;
the last P outcomes are kept for each instruction in VHT
in the form of a pattern which is 2P bits long
There are 22P entries in the PHT.
For each PHT entry, the next outcome likelihood is recorded,
via four independent up/down counter values:
{C1, C2, C3, C4}
Note that prediction is made only if the maximum is above a threshold.
If it is below the threshold, no prediction is made.
a. Contents get shifted left by 2 bits.
b. New outcome is entered into the bits left vacant.
a. Selected counter (corresponding to the correct outcome)
gets incremented
by 3 (or less, if 3 generates the saturation).
b. All other counters get decremented by one (unless they are zero).
The HYBRID Predictor
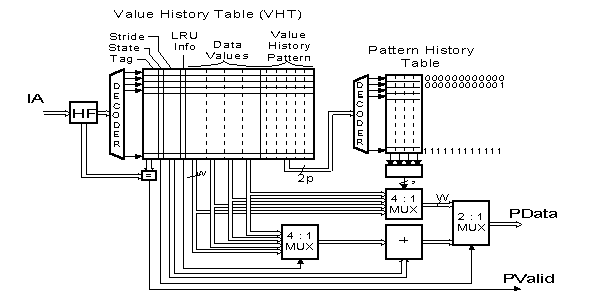 Combination of TWO-LEVEL and STRIDE-BASED predictors.
Combination of TWO-LEVEL and STRIDE-BASED predictors.
The VHT includes two additional fields: STATE and STRIDE
Figure7: Block Scheme of a Hybrid (Two-Level and Stride-Based) Predictor
Prediction Algorithm:
Performance Evaluation:
(i) MIPS-I ISA (integer instructions only)
(ii) SPEC'95 (integer suite only)
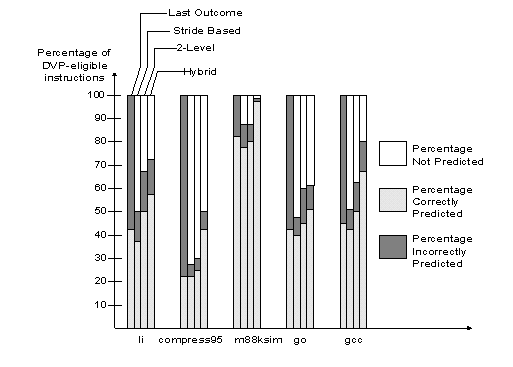
Figure8: Simulation Results for Different Predictors
The TRACE BASED Predictor - Value Oriented
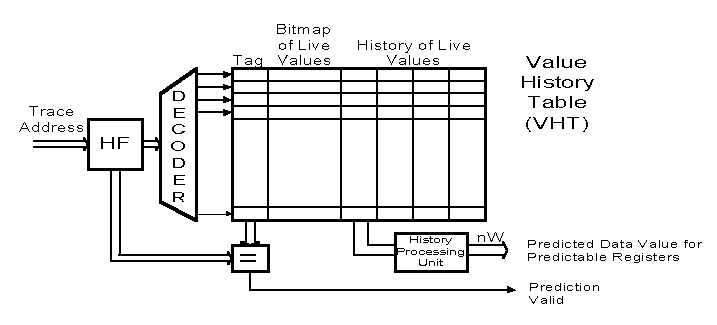
Figure9: Block Scheme of a Trace Based Predictor - Value Oriented
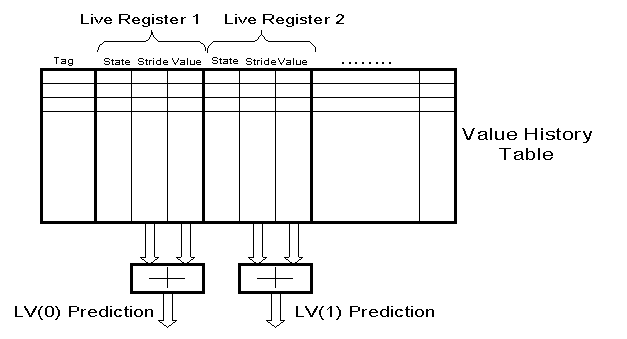
The TRACE BASED Predictor - Stride Oriented
Figure10:
Block Scheme of a Trace Based Predictor - Stride Oriented
The TWO LEVEL TRACE BASED Predictor
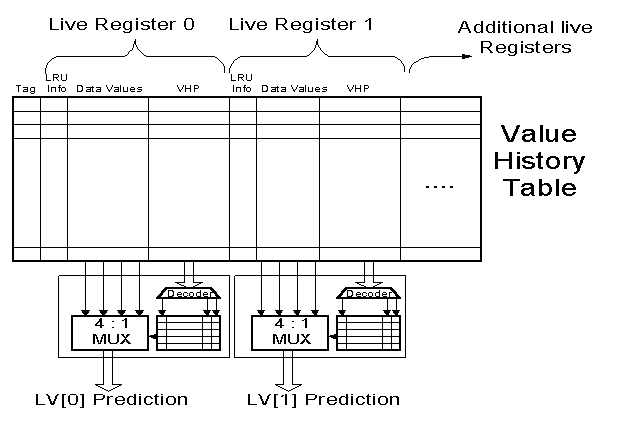
Figure11
: Block Scheme of a Two Level Trace Based Predictor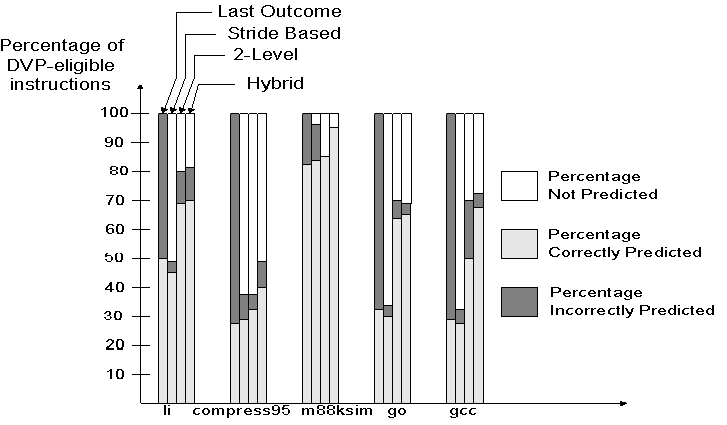
The TRACE BASED Predictor SIMULATION RESULTS
Figure12
: Simulation Results for Trace Based Predictors
Veljko Milutinovic
DPS: State-of-the-Art
Veljko Milutinovic
DPS: IFACT